
.svg?format=pjpg&auto=webp)
.svg?format=pjpg&auto=webp)
.png?format=pjpg&auto=webp)






.png?format=pjpg&auto=webp)
Hidden patterns in embedding optimization — Part I



Embeddings serve as the foundation of many AI applications, transforming raw data into meaningful vector representations. Learn how Principal Component Analysis (PCA) can be used to optimize vector storage, making Large Language Model (LLM) personalization, especially when using Retrieval-Augmented Generation (RAG), more practical and efficient.
As Generative AI becomes more prevalent, the need for efficient vector storage in Large Language Models (LLMs) is more important than ever. Embeddings serve as the foundation of many AI applications, transforming raw data into meaningful vector representations. However, the challenge of managing high-dimensional embeddings necessitates optimization strategies to reduce storage costs and improve processing efficiency.
This article bridges theory and practice by demonstrating how Principal Component Analysis (PCA) can be used to optimize vector storage, making Large Language Model (LLM) personalization, especially when using Retrieval-Augmented Generation (RAG), more practical and efficient.
The Challenge of Vector Storage
A key consideration when working with vector databases is storage efficiency. Converting text snippets or images into vectors and storing them in the database can increase infrastructure costs due to the significant size of each vector, especially with high dimensionality. For example, a single 1536-dimensional vector can be around 14 KB.
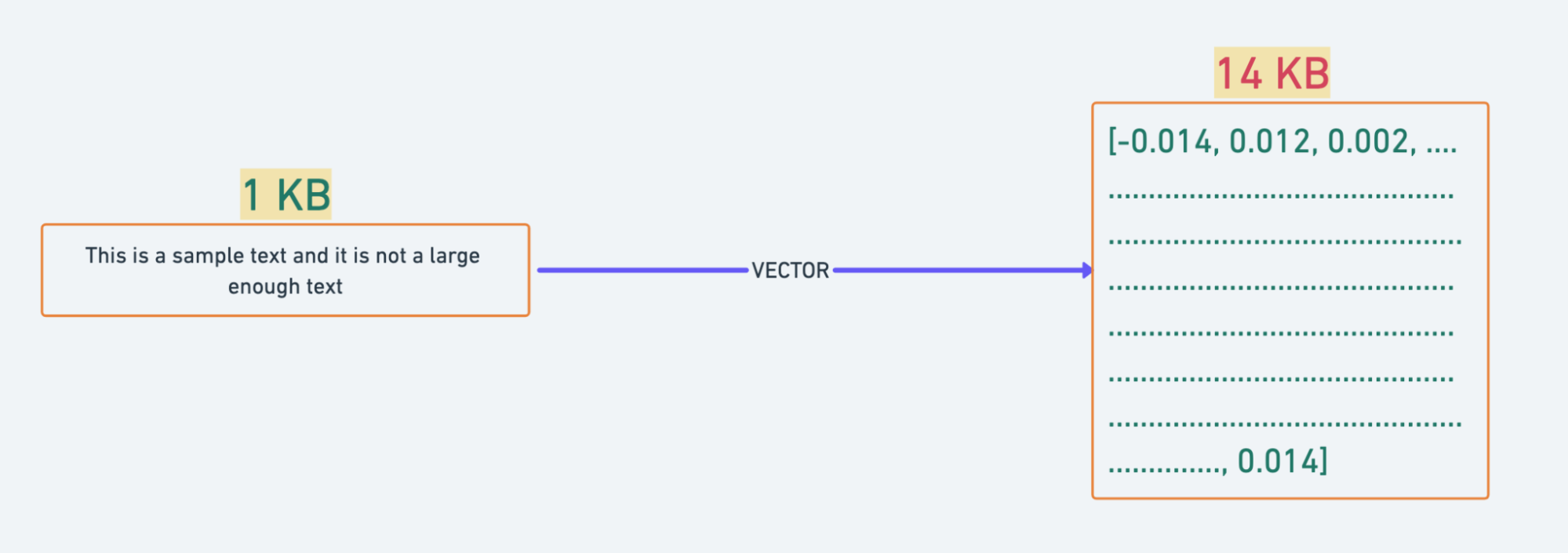
However, there's a trade-off; if each text chunk processed is 1024 characters long, the raw data size is only about 1 KB. This suggests that our text representation might be overparameterized, resulting in unnecessarily large vectors.
Principal Component Analysis to the Rescue
Principal Component Analysis (PCA) captures the essential components of vector representations, effectively reducing dimensionality and significantly cutting storage requirements. This helps tackle the challenge of overly detailed embeddings
PCA can reduce vector dimensionality, capture the most informative aspects, and minimize storage requirements without sacrificing performance.
Image Credit: Principal Component Analysis (PCA) Explained Visually with Zero Math
Optimizing Vector Storage
This section outlines a systematic strategy for improving vector storage efficiency without compromising accuracy. By setting up a vector database, ingesting data with a high-quality vectorizer, conducting iterative analysis, measuring precision, and optimizing dimensions, storage requirements were significantly reduced while maintaining high precision in vector representations.
- Vector Database Setup: A vector database was established to store and manage embeddings efficiently.
- Data Ingestion: The dataset was ingested into the vector database using the text-embedding-ada-002 vectorizer, known for generating high-quality text embeddings.
- Iterative Analysis: A series of analyses were conducted, focusing on calculating precision while systematically reducing vector dimensions. This iterative process allowed observation of how dimensionality reduction affected accuracy.
- Precision Measurement: With each iteration of dimension reduction, the precision of the model was measured to understand the trade-off between vector size and accuracy.
- Optimization: By analyzing the results of each iteration, the optimal number of dimensions that balanced storage efficiency with precision was identified.
This methodical approach allowed fine-tuning of embeddings, significantly reducing storage requirements while maintaining a high level of accuracy in vector representations.
Key Observations
After conducting the experiments, the following results were observed:
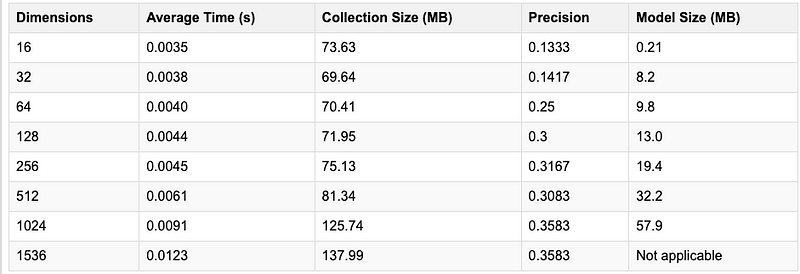
Performance Impact on Time
- Precision vs. Latency: Reducing dimensionality from 1536 to 512 results in a 14% drop in precision but decreases average latency by 50%, effectively doubling the capacity for calls.
- Maintaining Precision: Using 1024 dimensions maintains the same precision while reducing latency by 27%.
- Context-Specific Use Cases: Dimensionality below 512 is not ideal for Retrieval-Augmented Generation (RAG) applications that require high context specificity.
Impact on Storage
- Storage Efficiency: The storage size required for vectors is reduced by 10% at 1024 dimensions and by 42% at 512 dimensions.
- Overhead Consideration: Implementing dimensionality reduction introduces additional storage overhead.
Future Directions
- Scaling this methodology for millions of vectors without memory issues.
- Identifying optimal datasets for data modeling.
- Detecting data drift and determining when to rerun dimensionality reduction.
- Establishing the ideal top-k to match your Recall rate.
About Contentstack
The Contentstack team comprises highly skilled professionals specializing in product marketing, customer acquisition and retention, and digital marketing strategy. With extensive experience holding senior positions at renowned technology companies across Fortune 500, mid-size, and start-up sectors, our team offers impactful solutions based on diverse backgrounds and extensive industry knowledge.
Contentstack is on a mission to deliver the world’s best digital experiences through a fusion of cutting-edge content management, customer data, personalization, and AI technology. Iconic brands, such as AirFrance KLM, ASICS, Burberry, Mattel, Mitsubishi, and Walmart, depend on the platform to rise above the noise in today's crowded digital markets and gain their competitive edge.
In January 2025, Contentstack proudly secured its first-ever position as a Visionary in the 2025 Gartner® Magic Quadrant™ for Digital Experience Platforms (DXP). Further solidifying its prominent standing, Contentstack was recognized as a Leader in the Forrester Research, Inc. March 2025 report, “The Forrester Wave™: Content Management Systems (CMS), Q1 2025.” Contentstack was the only pure headless provider named as a Leader in the report, which evaluated 13 top CMS providers on 19 criteria for current offering and strategy.
Follow Contentstack on LinkedIn.

Recommended posts



