Find out why businesses are turning to vector databases
Share

Learn how vector databases handle complex and high-dimensional data and how they are used in AI and ML applications such as recommender systems, image recognition, recommendation and anomaly detection.
Highlights
You'll learn about why your business needs a vector database:
- Manage high-dimensional data: Effectively process complex data like text, images and audio with numerical embeddings
- Increase search and efficiency: Use similarity searches to enhance recommendation systems and detect anomalies in real-time
- Enhance AI and machine learning capabilities: Power use cases like recommendation systems, similarity searches and anomaly detection
Did you know that together, all of us generate 328.77 million terabytes of data daily? With the vast amount of data created, traditional databases can have a tough time keeping up with the needs of today's applications. That's where vector databases step in. They bring a fresh, smarter way to store, retrieve and manage data. Unlike traditional databases, vector databases handle the complexity and scale of vector data, helping you extract insights and perform real-time analysis. Such efficiency is perfect for machine learning and AI applications.
Scroll down to learn what these databases are and how they work.
What is a vector database?
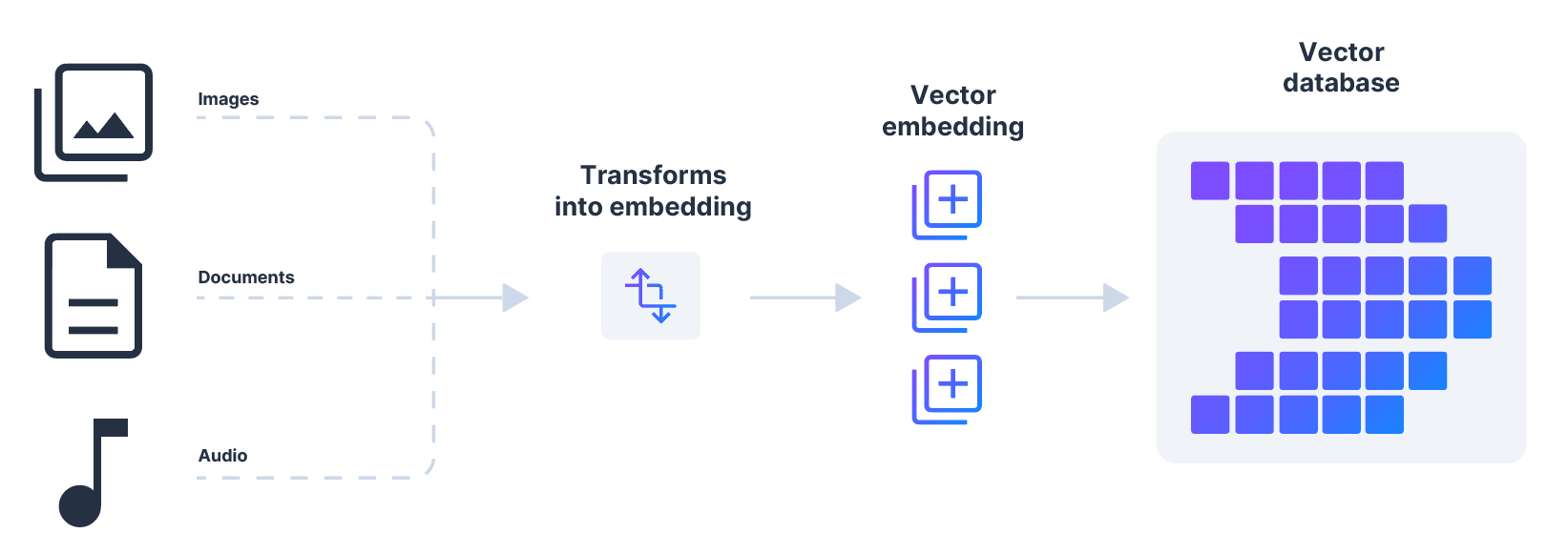
Vector databases are collections of data stored as mathematical representations. They can handle and search through high-dimensional vector data. While traditional databases work with rows and columns, vector databases work with unstructured or semi-structured data like text, images or audio. They store this data as numerical embeddings created by machine learning algorithms. As a result, it becomes easier to process and analyze complex information.
With these databases, you:
- Perform similarity search
- Group data together
- Complex complex queries
- Discover new insights
- Enhance recommendation systems
- Monitor and detect abnormal behavior in real time
For instance, when searching for a book in a bookstore, an employee recommends books based on your interest. Similarly, when shopping online, you see recommendations under a header like "You might also like..." Vector databases enable machine learning models to identify similar items, just as the bookstore employee finds related books and online stores suggest comparable products. (The online store uses a machine learning model to make recommendations.)
Elevate your content strategy with Contentstack AI: Streamline operations, boost efficiency and personalize user experiences effortlessly with AI automation. Embrace the future now!
Core components of vector databases
Vector databases meet the growing demands of complex AI applications using these components:
Fault tolerance and performance
Vector databases are designed to run smoothly 24/7, even during unexpected failures. They should handle heavy workloads and large-scale operations while delivering lightning-fast query responses. As a result, they're perfect for real-time applications where downtime is simply not an option.
Support for machine learning and AI applications
The databases can be deployed with machine learning frameworks such as TensorFlow, PyTorch and Scikit-learn, among others. They can store and index vector embeddings to improve the AI environment.
Integration with programming frameworks
Vector databases use APIs and SDKs that support programming languages like Python, JavaScript, Java and C++. As a result, developers can adopt new technologies and integrate databases into their applications.
Similarity searches
Vector databases can perform similarity searches at scale. Advanced algorithms like Approximate Nearest Neighbor (ANN) search and Hierarchical Navigable Small World (HNSW) graphs make finding similar data points fast and accurate, even in datasets with billions of entries. This capability is handy for recommendation systems, facial recognition and natural language processing.
How do vector databases work?
The first step is to transform data into vectors using techniques like embedding, which captures the semantic meaning of the data. For example, you transform images and audio into image and audio embedding. These embeddings are stored in vector databases optimized for high-dimensional data. Vector databases use intelligent algorithms for handling and searching through vector embeddings. These algorithms employ methods like hashing, quantization or graph-based search to carry out what's known as an approximate nearest neighbor (ANN) search.
When you need to find something, an ANN search locates the closest vector neighbor to your query. While it might not be as spot-on as the kNN search (known nearest neighbor or true k nearest neighbor algorithm), it's easier on your computer's resources. This makes ANN searches a fantastic option for efficiently managing large datasets with high-dimensional vectors, even if they sacrifice some accuracy for speed and scalability.
Vector databases vs traditional databases
Aspect | Traditional databases | Vector databases |
Data structure | Organizes data in structured tables with rows and columns; often uses schemas to define relationships. | Stores data as high-dimensional vectors, focusing on numeric representations of unstructured data like text, images or audio. |
Use cases | Ideal for structured data management applications, such as financial, inventory and transactional systems. | Built for tasks like recommendation systems, semantic search, NLP (Natural Language Processing) and AI-based applications. |
Data representation | Designed for relational or structured data (e.g., names, dates, numbers). | Personalized for unstructured data (e.g., embeddings from ML models). Captures contextual meaning in vector form. |
Querying | Uses SQL. Queries focus on exact matches or traditional filters on structured data. | Uses ANN or similarity search for approximate nearest neighbor queries based on distance between vectors. |
Performance | Highly optimized for consistent and reliable transactional performance (OLTP/OLAP scenarios). | Engineered for high-speed similarity searches, even in massive datasets. Performance depends on vector dimension and indexing methods. |
Indexing | Indexes are based on primary keys, foreign keys or secondary keys. | Employs specialized vector indexing like HNSW (Hierarchical Navigable Small World) or Annoy for rapid data retrieval. |
Data retrieval | Focuses on matching exact data values or predefined conditions. | Ranks and retrieves results based on proximity or similarity score (e.g., cosine similarity or Euclidean distance). |
Scalability | You can add resources to a single node or distribute them across nodes. | Designed to scale for large datasets requires intensive vector computation. |
Processing efficiency | Suited for processing structured, transactional datasets efficiently with ACID compliance. | Optimized for tasks involving similarity comparison or clustering of unstructured data. |
Integration | Well-suited for applications in ERP, CRM or legacy systems. | Often used in conjunction with machine learning frameworks like TensorFlow or PyTorch for feature storage and retrieval. |
Applications of vector databases
These are the use cases of vector databases:
AI-powered systems and large language models (LLMs)
In AI-powered systems that use LLMs, vector databases can process data more efficiently and make accurate predictions. These databases can improve AI models, helping you easily store and retrieve vector embeddings.
Personalization
Vector databases use demographic details, data and past purchases to provide personalized products and services while meeting users' needs and wants. In e-commerce, vector databases produce customized product suggestions based on customers' likes and previous purchases. Streaming services like Netflix use vector databases to track users' watching patterns and recommend suitable shows or movies. On social media, vector databases power customized news feeds and targeted ads, making users' experiences feel more relevant and engaging.
Personalization works best when you balance user privacy, scalability, speed, data quality, adaptability and transparency. Protect user data with strong security practices while ensuring your systems can handle large-scale, real-time needs. Keep your data accurate and clean and use continuous learning to stay in tune with changing user behaviors. Most importantly, make your recommendations clear and easy to understand so users can trust the process.
Recommendation engines
Popular recommendation systems, like those on streaming platforms or e-commerce sites, need to compare user preferences. They do this with billions of data points. This is where vector databases are helpful. Vector databases focus on similarity searches. They help recommendation engines suggest products or content that a shopper or browser might like.
Image recognition
Vector databases are useful in identifying images. Images are transformed into high-dimensional vectors using convolution neural networks (CNNs). Vector representations make image classification and analysis faster and more accurate. These databases facilitate facial recognition, object detection and content-based image search, improving experiences.
Content discovery
With vector search capabilities, you enhance information retrieval in the media, publishing and entertainment industries. Vector embeddings match content based on user intent, improving engagement and customer satisfaction.
Generative AI
Vector databases help generative AI by making it easy to store and access complex data for training models. They also allow similarity searches to find similar data, generating relevant and coherent results. Vector databases work smoothly with AI tools, supporting scalable and faster data processing.
Data analysis
Vector databases improve the quality of data analysis by easily and efficiently managing multi-dimensional data. As the database can scale, you can study patterns in genomics and meteorology.
Anomaly detection in security and finance
Vector databases excel at detecting real-time security breaches, credit card frauds or financial frauds in high dimensional space.
How are vector databases implemented to enable the Contentstack AI platform?
Vector databases are used in Contentstack's AI platform to create smarter, more personalized content experiences. They convert text into high-dimensional mathematical representations to discover the relationships between words, phrases and documents. As a result, you get better similarity searches, smarter recommendations and intelligent content matching.
With vector databases, Contentstack can index and search for large amounts of content. This helps its AI understand the details in its content library. The result?
Real-time, personalized experiences that engage users and drive business results.
Vector databases work with other AI-powered platforms, providing superior content management and automation features. Contentstack helps users see what the content can do for them, streamlines processes and creates never-before-experiences.
Transform your workflow with Contentstack AI: Up-level your workflow with AI-driven content management. Save time, automate processes and focus on innovation. Discover the power of automation.
Vector databases in machine learning
In machine learning models, these databases improve content discovery to provide users with relevant content. They are helpful in recommendation, search and natural language processing tasks.
Handling high-dimensional data
Traditional databases cannot index, query or work with high-dimensional data. That's why companies rely on vector databases. They allow faster data processing, even with hundreds or thousands of dimensions.
Improving search and retrieval
Vector databases can perform similarity-based search, which involves finding the closest match to a given query vector. Real-world applications include facial recognition systems that match similar faces and a recommendation system that recommends products to the user.
Supporting AI applications
You can use vector databases in AI applications for clustering, classification and semantic search. For instance, machine learning models use these databases to group similar data points or retrieve content with similar meanings.
FAQs
What is a vector database?
A vector database stores and retrieves high-dimensional vectors. It's used in AI, ML, search engines and semantic search applications.
What are some examples of vector databases?
Pinecone, Milvus, Weaviate and FAISS are vector databases renowned for their performance and integration capabilities.
How do vector embeddings work?
Vector embeddings translate data (like text or images) into mathematical representations that capture semantic relationships. This enables the querying of similar data points.
Learn more
Vector databases are purpose-built databases that overcome the shortcomings of managing vector embedding. They offer more advantages than traditional databases that work with rows and columns. As these databases handle high-dimensional vectors, perform semantic searches and integrate with ML workflows, they're perfect for companies looking to extract deeper insights from their data.
If you want to see these tools in action and discover what they can do for you, talk to us.


