
Beyond the Black Box — Demystifying LLM fine-tuning with data-driven insights

Share

Large language models (LLMs) are exceptional tools, offering portability, dense information, and broad deployability. Writers leverage them to overcome writer’s block, developers use them as pair programmers, and students see them as a last-minute lifeline for assignments. While LLMs are powerful in their default state, their true potential shines when personalized for specific tasks.
Have you ever wondered how AI models can be tailored to meet your specific needs? Let's dive into the world of fine-tuning large language models (LLMs) to find out!
Large language models (LLMs) are exceptional tools, offering portability, dense information, and broad deployability. Writers leverage them to overcome writer’s block, developers use them as pair programmers, and students see them as a last-minute lifeline for assignments. While LLMs are powerful in their default state, their true potential shines when personalized for specific tasks.
Let's explore how to personalize portable LLMs without diving too deeply into technical details.
Using Retrieval-Augmented Generation (RAG)
RAG enhances LLMs by providing hints as embeddings alongside prompts. This method personalizes LLMs temporarily by enriching input data. For more enduring customization, fine-tuning is employed.
Fine-Tuning – Overview and Experiments
Fine-tuning involves adjusting only a portion of an LLM’s parameters rather than training the entire model from scratch. This selective training, where certain model weights remain "frozen," results in a model that retains new information more permanently than RAG.
Experiments with fine-tuning LLMs used internal HR documentation supported by an in-house framework for fine-tuning, inference, evaluation, and experiment tracking. We tested models like Llama 3 8b, Mistral 7b v0.2 and v0.3, Gemma 2b, and Phi 2 medium.
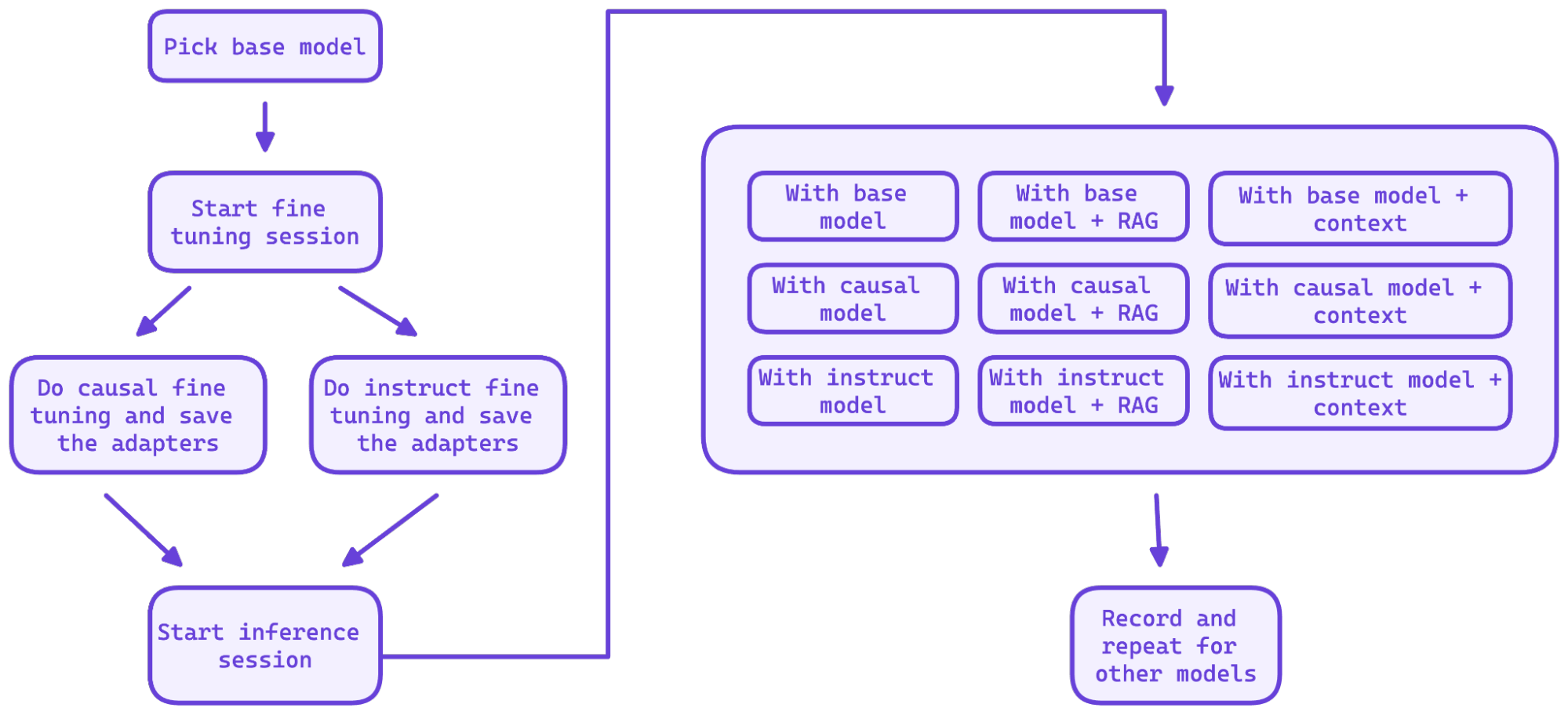
Various fine-tuning methods with and without RAG were applied, providing insights into selecting the right LLMs for specific tasks.
Technical Breakdown
High-quality datasets are crucial for effective fine-tuning. The framework generates these datasets using Ollama and prompt engineering to generate these datasets. Contentstack provided an NVIDIA A10 GPU with 24GB VRAM for the experiments, with each fine-tuning run taking about 1.5 hours.
We employed several methodologies, and found that QLoRA (quantized LoRA) with 4-bit precision yielded the best results. To optimize the fine-tuning process, various hyper-parameters were also tested, a time-consuming task, particularly for models like Mistral 7b v0.2.
After determining the optimal hyper-parameters, we conducted causal and instructed fine-tuning, saving the adapters to a private HuggingFace repository for easy deployment. The evaluation session assessed fine-tuned models against a curated dataset using metrics like BLEU, ROUGE, and n-gram similarity. Additionally, a RAGA feature was implemented for subjective evaluation, scoring outputs on accuracy and relevance.
Outcome and Findings
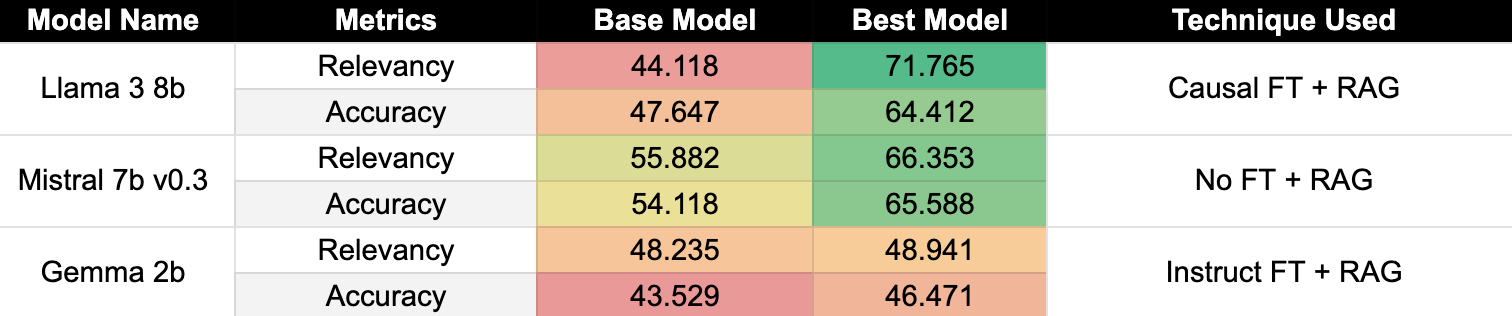
Results revealed:
- Instruct fine-tuning with RAG underperformed compared to the base model for Mistral 7b v0.3 and Llama 3 8b.
- Causal fine-tuning outperformed instruct fine-tuning for Mistral 7b v0.3.
- Smaller models like Gemma 2b benefited significantly from instruct fine-tuning with RAG.
These findings highlight the heuristic nature of LLMs and their varied performance based on the use case.
We also analyzed raw textual metrics such as BLEU, ROUGE, and n-gram similarity. These metrics, averaged over all prompts, provide additional insights but should be interpreted cautiously.
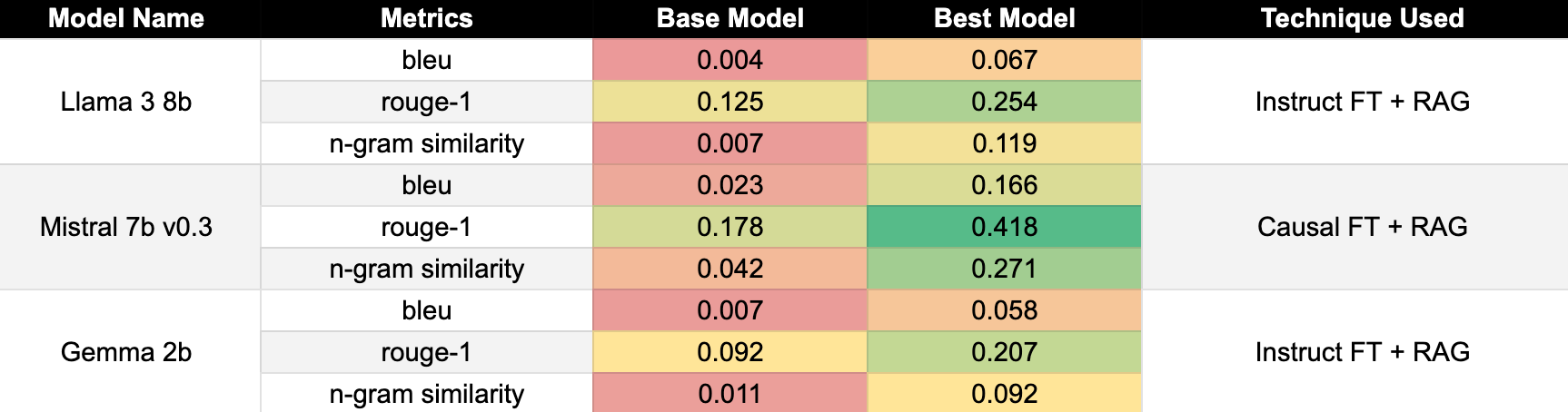
The experiments demonstrated that fine-tuning substantially benefits smaller models, while larger models show less significant gains. These insights enable the selection of cost-effective models tailored to specific tasks.
Conclusion
Fine-tuning LLMs can significantly enhance their performance for specific tasks, especially for smaller models. By carefully selecting and customizing LLMs, users can achieve cost-effective, high-performing AI solutions. Explore these techniques in your own projects and unlock the full potential of LLMs.


